RPython 工具链¶
内容
本文档描述了我们开发的工具链,用于分析和“编译”RPython 程序(例如 PyPy 本身)到各种目标平台。
它包含三个主要部分:一个略微简化的概述,对我们工具链中每个主要组件的简要介绍,然后是一个更全面的部分,描述这些组件是如何协同工作的。如果您是第一次阅读本文档,那么概述 可能是最有用的;如果您正在尝试刷新您对 PyPy 的记忆,那么它们是如何协同工作的 可能正是您想要的。
概述¶
翻译工具链的任务是将 RPython 程序转换为该程序在一个或多个目标平台上的高效版本,通常是比 Python 更底层的平台。它将此任务划分为几个步骤,本文档的目的是介绍这些步骤。
首先,我们描述将RPython程序转换为 C 代码的过程(这是默认的和最初的目标)。
RPython 翻译工具链永远不会看到 Python 源代码或语法树,而是从定义您作为输入提供的函数对象的执行行为的代码对象开始。 流程图构建器 使用抽象解释遍历这些代码对象,为每个函数生成一个控制流图:源程序的另一种表示形式,但它适合应用类型推断和翻译技术,并且是大多数翻译步骤操作的基本数据结构。
将翻译视为由以下步骤组成是很有帮助的(另请参见下图)
- 导入完整的程序,此时可以执行任意的运行时初始化。完成后,程序必须以RPython意义上“足够静态”的形式存在于内存中。
- 注解器从指定的入口点开始执行全局分析,以推断每个变量在运行时可能包含的内容的类型和其他信息,并在遇到它们时构建流程图。
- RPython 类型器(或 RTyper)使用注解器推断的高级信息将控制流图中的操作转换为低级操作。
- 在 RTyper 之后,可以应用一些可选的优化,这些优化旨在使生成的程序运行得更快。
- 下一步是准备流程图以生成源代码,这涉及计算程序中各种函数和类型在最终源代码中将具有的名称,并应用插入显式异常处理和内存管理操作的转换。
- C 后端(口语上称为“GenC”)生成多个 C 源文件(如上所述,我们现在忽略其他后端)。
- 编译这些源文件以生成可执行文件。
(尽管从这个演示来看,这些步骤并非像您想象的那样截然不同)。
翻译过程有一个名为rpython/bin/translatorshell.py的交互式界面,允许您以交互方式完成这些阶段。
下图给出了一个简化的概述(PDF 彩色版本)
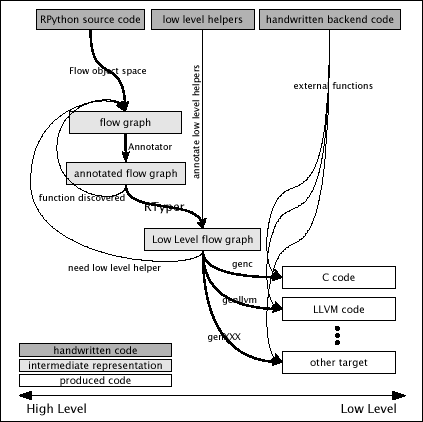
构建流程图¶
简介¶
流程图构建器(源代码位于rpython/flowspace/)的任务是从函数生成控制流图。该图还将包含单个操作的跟踪,因此它实际上只是函数的另一种表示形式。
基本思想是,如果给定一个函数,例如:
def f(n):
return 3*n+2
解释器会将其编译成字节码,然后在其虚拟机上执行它。相反,流程图构建器包含一个抽象解释器,它获取字节码并执行任何必要的栈操作和变量操作,但仅将对 Python 对象执行的任何实际操作记录到称为基本块的结构中。操作的结果由一个占位符值表示,该值可以出现在进一步的操作中。
例如,如果将占位符v1作为上述函数的参数,字节码解释器将调用v2 = space.mul(space.wrap(3), v1),然后v3 = space.add(v2, space.wrap(2)),并返回v3作为结果。在这些调用期间,将记录以下块
Block(v1): # input argument
v2 = mul(Constant(3), v1)
v3 = add(v2, Constant(2))
抽象解释¶
build_flow()通过将字节码解释器发出的所有操作记录到基本块中来工作。基本块在两种情况下结束:当字节码解释器调用is_true()时,或者当到达连接点时。
- 当下一个操作即将记录到当前块中,但已经有另一个块记录了相同字节码位置的操作时,就会发生连接点。这意味着字节码解释器已经关闭了一个循环,并且正在再次解释已经看过的代码。在这种情况下,我们会中断字节码解释器,并从当前块的末尾到前一个块创建一个链接,从而在流程图中也关闭循环。(请注意,这仅在即将记录操作时发生,这允许进行一定程度的常量折叠)。
- 如果字节码解释器调用
is_true(),抽象解释器通常不知道答案应该是 True 还是 False,因此它会放置一个条件跳转,并为当前基本块生成两个后继块。有一些技巧可以让字节码解释器认为is_true()首先返回 False(后续操作记录在第一个后继块中),稍后对is_true()的相同调用也返回 True(这次后续操作转到另一个后继块)。
(本节待扩展…)
流程模型¶
在这里,我们描述了build_flow()生成的数据结构,它们是翻译过程的基本数据结构。
所有这些类型都在rpython/flowspace/model.py中定义(这是 PyPy 源代码库中一个相当重要的模块,以强调这一点)。
函数的流程图由类FunctionGraph表示。它包含对Block集合的引用,这些集合由Link连接。
一个Block包含一个SpaceOperation列表。每个SpaceOperation都有一个opname和一个args和result列表,它们要么是Variable要么是Constant。
我们有一个非常有用的 PyGame 查看器,它允许您在翻译过程的不同阶段直观地检查流程图(对于尝试找出问题所在非常有用)。它看起来像这样
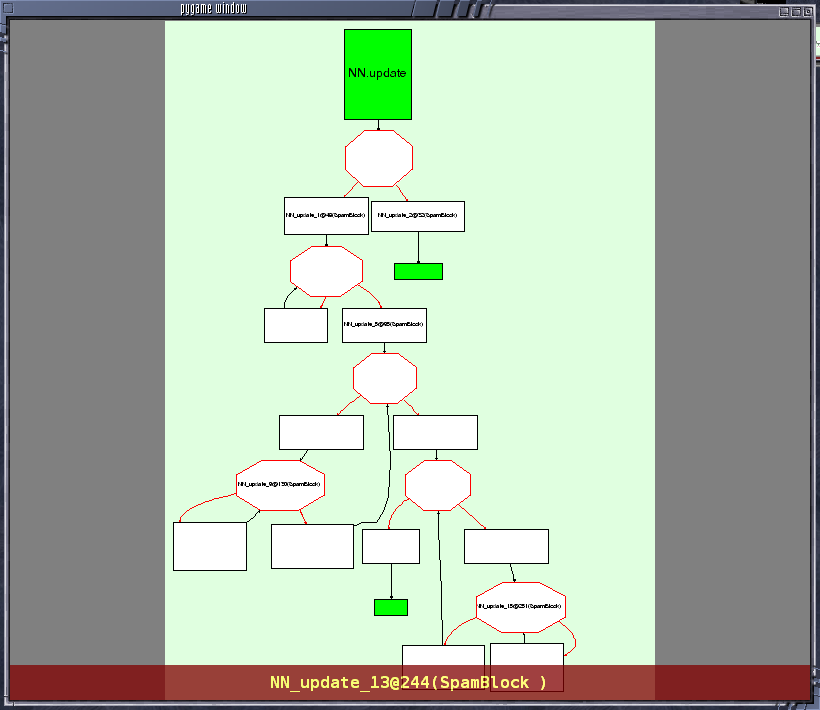
建议在几个示例上使用python bin/translatorshell.py进行练习,以了解流程图的结构。下面详细描述了类型及其属性
FunctionGraph一个流程图容器(对应于一个函数)。
startblock 第一个块。当调用函数时,控制权会转移到此处。startblock 的输入参数是函数的参数。如果函数采用 *args参数,则args元组作为 startblock 的最后一个输入参数给出。returnblock 执行函数返回的(唯一)块。它是空的,实际上不包含任何 return操作;返回是隐式的。返回值是 returnblock 的唯一输入变量。exceptblock 从函数中引发异常的(唯一)块。两个输入变量分别是异常类和异常值。(如果函数没有显式引发异常,则没有其他块会实际链接到 exceptblock)。 Block一个基本块,包含一系列操作并以跳转到其他基本块结束。在块执行期间“存活”的所有值都存储在变量中。每个基本块都使用其自己独特的变量。
inputargs 表示可以从任何前一个块进入此块的所有值的全新、不同的变量列表。 operations SpaceOperations 列表。 exitswitch 见下文 exits 表示从该基本块末尾到其他基本块开头的可能跳转的 Link 列表。 每个 Block 以以下方式之一结束
- 无条件跳转:exitswitch 为 None,exits 包含单个 Link。
- 条件跳转:exitswitch 是 Block 中出现的变量之一,exits 包含一个或多个 Link(通常为 2 个)。每个 Link 的 exitcase 给出一个具体的值。这相当于一个“switch”:控制权遵循其 exitcase 与 exitswitch 变量的运行时值匹配的 Link。如果变量与任何 exitcase 不匹配,则为运行时错误。
- 异常捕获:exitswitch 为
Constant(last_exception)。第一个 Link 的 exitcase 设置为 None,表示非异常路径。接下来的 Link 的 exitcase 设置为 Exception 的子类,当基本块的最后一个操作引发匹配的异常时,将执行这些 Link。(因此基本块不能为空,并且只有最后一个操作受处理程序保护。) - 返回或异常:returnblock 和 exceptblock 的操作设置为空元组,exitswitch 设置为 None,exits 为空。
Link从一个基本块到另一个基本块的链接。
prevblock 此 Link 作为其出口的 Block。 target 此 Link 指向的目标 Block。 args 变量和常量的列表,大小与目标 Block 的 inputargs 相同,它给出传递到下一个块的所有值。(请注意,prevblock 中使用的每个变量都可能在 args列表中出现零次、一次或多次。)exitcase 见上文。 last_exception None 或变量;见下文。 last_exc_value None 或变量;见下文。 请注意,
args使用 prevblock 中的变量,这些变量按位置与目标块的inputargs匹配,就像元组赋值或函数调用一样。如果链接是异常捕获链接,则
last_exception和last_exc_value将设置为两个新的变量,这些变量被认为是在进入链接时创建的;在运行时,它们将分别保存异常类和值。这两个新变量只能在同一个链接的args列表中使用,以传递到下一个块(照常,它们实际上可能根本不出现,或者在args中出现多次)。SpaceOperation记录的(或以其他方式生成的)基本操作。
opname 操作的名称。 build_flow()仅生成rpython.flowspace.operation中列表中的操作,但稍后可以任意更改名称。args 参数列表。每个参数都是之前在基本块中看到的常量或变量。 result 将结果存储到其中的新变量。 请注意,操作通常不能在运行时隐式引发异常;例如,代码生成器可以假设对列表的
getitem操作是安全的,并且可以在没有边界检查的情况下执行。此规则的例外情况是:(1)如果操作是块中的最后一个操作,并且以exitswitch == Constant(last_exception)结束,则必须检查、生成和适当地捕获隐式异常;(2)对其他函数的调用,如simple_call或call_args,始终可以引发被调用函数可能引发的任何异常——并且此类异常必须传递到父级,除非它们如上所述被捕获。Variable运行时值的占位符。这里主要是一些调试内容。
name 尽管 name保证唯一,但最好使用 Variable 对象本身而不是其name属性来引用值。Constant用作 SpaceOperation 参数的常量值,或用作通过 Link 传递的值以初始化目标 Block 中的输入变量。
value 此 Constant 表示的具体值。 key 表示值的散列对象。 Constant 偶尔可以存储可变的 Python 对象。它表示该对象的静态、预初始化、只读版本。流程图不应尝试实际修改此类 Constant。
注释传递¶
我们在下面简要描述了如何“注释”控制流图以发现对象的类型。此注释传递是一种类型推断的形式。它对 Flow Object Space 生成的控制流图进行操作。
有关注释过程的更全面描述,请参阅我们关于翻译的欧盟报告中的相应部分。
注释器的主要目标是“注释”流程图中出现的每个变量。“注释”根据对所有流程图(每个函数一个)的整个程序分析,描述了此变量在运行时可能包含的所有可能的 Python 对象。
“注释”是 SomeObject 的子类的实例。每个子类都表示特定类型的对象族。
以下是概述(参见 pypy/annotation/model/)
SomeObject是基类。SomeObject()的实例表示任何 Python 对象,因此通常意味着输入程序不是完全的 RPython。SomeInteger()表示任何整数。SomeInteger(nonneg=True)表示非负整数(>=0)。SomeString()表示任何字符串;SomeChar()表示长度为 1 的字符串。SomeTuple([s1,s2,..,sn])表示长度为n的元组。此元组中的元素本身受给定注释列表的约束。例如,SomeTuple([SomeInteger(), SomeString()])表示一个有两个项目的元组:一个整数和一个字符串。
注释传递的结果本质上是一个大型字典,它将 Variable 映射到注释。
所有 SomeXxx 实例都是不可变的。如果注释器需要修改其关于变量可以包含什么的信念,它会通过创建一个新的注释来做到这一点,而不是修改现有的注释。
可变值和容器¶
可变对象在注释期间需要特殊处理,因为包含值的注释需要可能更新以解释变异操作,因此注释信息会通过流程图的相关部分重新流动。
SomeList代表一个同质类型列表(即列表的所有元素都由单个公共SomeXxx注释表示)。SomeDict代表一个同质字典(即所有键都具有相同的SomeXxx注释,所有值也一样)。
用户定义的类和实例¶
SomeInstance 代表给定类或其任何子类的实例。对于注释器看到的每个用户定义的类,我们维护一个 ClassDef(pypy.annotation.classdef),描述类的实例的属性;本质上,ClassDef 给出了所有类级别和实例级别属性的集合,并且对于每个属性,给出了相应的 SomeXxx 注释。
实例级别属性随着注释的进行而逐步发现。像
inst.attr = value
这样的赋值将更新给定实例的 ClassDef 以记录给定属性存在并且可以与给定值一样通用。
对于每个属性,ClassDef 还记录读取该属性的所有位置。如果稍后我们发现一个赋值迫使关于该属性的注释变得更通用,那么所有到目前为止读取该属性的位置都被标记为无效,并且注释器将从那里重新启动其分析。
实例级别属性和类级别属性之间的区别很小;类级别属性本质上被认为是实例级别属性的初始值。方法在这方面没有什么特别之处,除了当被视为实例的初始值时,它们绑定到实例(即 self = SomeInstance(cls))。
继承规则如下:两个 SomeInstance 注释的并集是最精确的公共基类的 SomeInstance。如果通过父类的 SomeInstance 考虑(即读取或写入)属性,那么我们假设所有子类也具有相同的属性,并且相同的注释适用于所有这些属性(因此代码如 return self.x 在父类的方法中强制父类及其所有子类具有属性 x,其注释足够通用以包含所有子类可能希望存储在 x 中的值)。但是,如果不同子类没有以通用方式通过父类使用,则它们可以具有相同名称但具有不同、无关注释的属性。
后端优化¶
后端优化的目的是使编译后的程序运行得更快。与 PyPy 翻译器的许多部分(与传统编译器非常不同)相比,其中大部分对于了解编译器工作原理的人来说将非常熟悉。
函数内联¶
为了减少运行 PyPy 解释器时发生的许多函数调用的开销,我们实现了函数内联。这是一种优化,它获取一个流程图和一个调用点,并将流程图的副本插入到调用函数的图中,并根据需要重命名发生的变量。如果原始函数被 try: ... except: ... 保护包围,这会导致问题。在这种情况下,内联并不总是可能的。但是,如果被调用函数没有直接引发异常(但异常可能由进一步调用的函数引发),则内联是安全的。
此外,我们还实现了启发式算法,用于内联函数。为此,我们为每个函数分配一个“大小”。此大小应大致对应于如果函数在某处内联,则代码大小预计会增加的幅度。此估计值是两个数字的总和:一方面,每个操作都分配一个特定的权重,默认权重为 1。某些操作被认为比其他操作需要更多工作,例如内存分配和调用;其他操作则被认为不需要任何工作(强制类型转换等)。大小估计值一方面是图中所有操作权重的总和。这称为“静态指令计数”。图的大小估计值的另一部分是“中位执行成本”。这再次是图中所有操作权重的总和,但这次用操作执行频率的猜测加权。为了得出这个猜测,我们假设在每个分支上,我们都以相同的频率选择两个路径,除了循环结束处的分支,其中跳回循环结束处的可能性更大。这会导致一个方程组,可以求解以获得所有操作的近似权重。
在确定所有函数的大小估计值后,将函数内联到其调用站点,从最小的函数开始。每次将一个函数内联到另一个函数中时,都会重新计算外部函数的大小。这样做直到剩余函数的大小都大于预定义的限制。
Malloc 删除¶
由于 RPython 是一种垃圾回收语言,因此始终会进行大量的堆内存分配,这在更传统的显式管理语言中要么根本不会发生,要么会导致一个在预先知道的时间死亡的对象,因此可以显式地释放。例如,以下形式的循环
for i in range(n):
...
它只是迭代从 0 到 n - 1 的所有数字,在 Python 中等效于以下内容
l = range(n)
iterator = iter(l)
try:
while 1:
i = iterator.next()
...
except StopIteration:
pass
这意味着执行了三次内存分配:范围对象、范围对象的迭代器和结束循环的 StopIteration 实例。
在进行少量内联后,这三个对象甚至从未作为参数传递给另一个函数,也未存储到全局可访问的位置。在这种情况下,可以删除该对象(因为它在函数返回后无论如何都会死亡),并可以用其包含的值替换它。
这种模式(分配的对象从未离开当前函数,因此在函数返回后死亡)经常出现,尤其是在进行了一些内联操作之后。因此,我们实现了一种优化,可以“展开”对象,从而在这种简单(但非常常见)的情况下节省一次分配。
准备源代码生成¶
这个也许命名略微模糊的阶段是最近作为单独步骤出现的。它的作用是在源代码生成之前做出最终的实现决策——经验表明,在实际生成源代码的同时,你真的不想进行任何思考。对于 C 后端,此步骤执行三件事
- 插入显式异常处理,
- 插入显式内存管理操作,
- 确定函数和类型在最终源代码中的名称(对象到名称的这种映射有时称为“低级数据库”。)
使异常处理显式化¶
RPython 代码可以像不受限制的 Python 一样自由地使用异常,但最终结果是 C 程序,而 C 没有异常的概念。异常转换器以类似于 CPython 的方式实现异常处理:异常由特殊的返回值指示,当前异常存储在全局数据结构中。
从某种意义上说,异常转换器的输入是用异常表示的 lltypesystem 方面的程序,输出是用裸 lltypesystem 表示的程序。
内存管理细节¶
除了具有异常之外,RPython 还是一种垃圾回收语言;同样,C 不是。为了解决这个问题,必须做出关于内存管理的决策。为了保持 PyPy 对灵活性的方法,可以自由地更改执行方式。目前实现了三种方法
- 引用计数(已弃用,太慢)
- 使用 Boehm-Demers-Weiser 保守式垃圾收集器
- 使用我们自定义的 在 RPython 中实现的精确 GC
几乎所有应用程序级 Python 代码都以非常快的速度分配对象;这意味着内存管理实现对于 PyPy 解释器的性能至关重要。
历史说明¶
正如本文所述,翻译步骤被划分为比人们最初预期的更多的步骤。它肯定被划分为比项目启动时我们预期的更多的步骤;GenC 的第一个版本对高级流程图和注释器的输出进行操作,甚至 RTyper 的概念也还不存在。最近,准备流程图以进行源代码生成(“数据库化”)和实际生成源代码最好被分别考虑这一事实变得清晰。
它们如何协同工作¶
到目前为止应该很清楚,PyPy 的翻译工具链是一个灵活而复杂的系统,由许多独立的组件组成。
digraph translation { graph [fontname = "Sans-Serif", size="6.00"] node [fontname = "Sans-Serif"] edge [fontname = "Sans-Serif"] subgraph legend { "输入或输出" [shape=ellipse, style=filled] "转换步骤" [shape=box, style="rounded,filled"] // 无形的边以确保它们垂直放置 "输入或输出" -> "转换步骤" [style=invis] } "输入程序" [shape=ellipse] "流程分析" [shape=box, style=rounded] "注释器" [shape=box, style=rounded] "RTyper" [shape=box, style=rounded] "后端优化(可选)" [shape=box, style=rounded] "异常转换器" [shape=box, style=rounded] "GC 转换器" [shape=box, style=rounded] "GenC" [shape=box, style=rounded] "ANSI C 代码" [shape=ellipse] "输入程序" -> "流程分析" -> "注释器" -> "RTyper" -> "后端优化(可选)" -> "异常转换器" -> "GC 转换器" "RTyper" -> "异常转换器" [style=dotted] "GC 转换器" -> "GenC" -> "ANSI C 代码" // "GC 转换器" -> "GenLLVM" -> "LLVM IR" }一个尚未强调的细节是各个组件之间的交互。说在注释器完成工作后,RTyper 处理图,然后使异常处理显式化,依此类推,这使得演示效果很好,但这并不完全正确。例如,RTyper 会插入对许多 低级辅助函数 的调用,这些辅助函数必须首先进行注释,并且 GC 转换器可以使用其某些小型辅助函数的内联(后端优化 之一)来提高性能。下图试图总结执行默认翻译过程每个步骤所涉及的组件
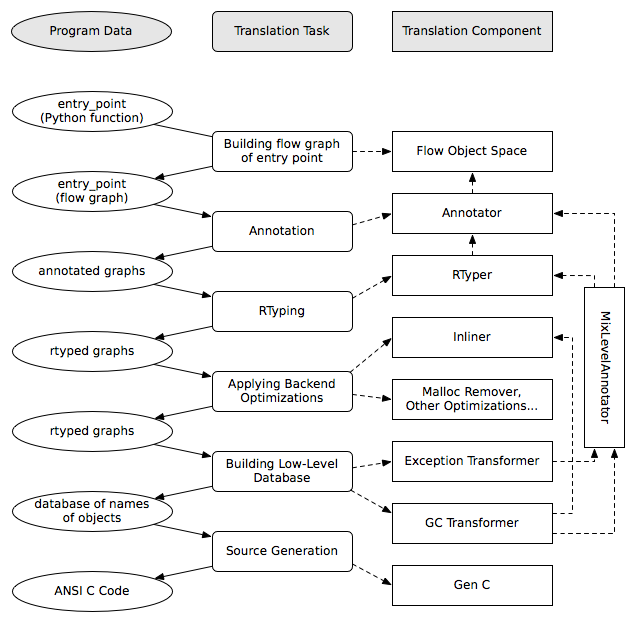
之前未提及的一个组件是“MixLevelAnnotator”;它为“后期”(在 RTyping 之后)翻译步骤提供了一个方便的接口,以便声明它需要能够调用一组函数(这些函数可能以相互递归的方式相互引用)并一次性对其进行注释和 rtype。